
Mamba, Differential Attention, and Beyond — Inside Dragon’s Design
Merging research innovations into a scalable, efficient architecture.

Why do so many research breakthroughs never reach production?
Despite an explosion of innovation in deep learning, nearly all Large Language Models still rely on the same architecture — the Transformer — introduced in 2017 by ‘Attention Is All You Need’. Since then, only minor updates like RoPE (2021), GQA (2023), QK Norm (2020), or Swiglu (2020) have been integrated, while hundreds of more advanced ideas remain unused.
This article explores what happens when these state-of-the-art techniques are finally combined into a single architecture. We review the fundamentals and limits of Transformers, how recent research addresses these issues, and how these advances led to the creation of Dragon, a new large-scale architecture that outperforms standard Transformers in efficiency, recall, and scalability.
The Basics of Transformers
The current Transformer architecture consists of two main layers:
Multi-Layer Perceptron — stores knowledge
Mixer Layer — self-attention in Transformers — determines how each word relates to previous words
Self-attention is the heart of the Transformer architecture. It examines every previous token in the sequence, enabling the model to retrieve information from context and follow instructions through in-context learning. However, self-attention has a major drawback: because it looks at every previous token for each token, it requires O(n²) computations and O(n) memory. For long sequences, this demands significant hardware resources.
Fun fact: Initially, the attention mechanism required O(n²) memory during training, which limited self-attention to 512–1024 tokens on GPUs of the time. Current LLMs exist only thanks to an online-computation of self-attention presented by Tri Dao in June 2022, which unlocked longer sequence lengths. This hardware-aware algorithm — now essential — has been refined over the years and is called Flash Attention. Version 4 was released a few weeks ago.
Transformer training is highly efficient, consisting almost exclusively of matrix multiplication, which current GPUs handle extremely well.
But Transformer inference is bottlenecked by memory.
Self-attention must examine each previous token, requiring it to be loaded from GPU memory. Memory speed hasn’t grown as fast as compute power on current GPUs — see SemiAnalysis: The Memory Wall.
Moreover, as sequence length grows, the memory usage of a single request grows as well, preventing many users from being served in parallel and degrading performance.
On very long sequences, the inference needs to split the sequence on multiple computers, which introduces significant communication overhead, resulting into high-cost for long-context requests.
In simple terms, traditional Self-Attention is like having every word in a sentence listen to all other words — effective for capturing context, but increasingly inefficient as the sequence grows longer.
Linear Attention and the Recall Issue
Self-Attention’s memory and compute limitations have sparked many attempts to create a linear version requiring only O(n) operations and fixed memory during inference.
Imagine a group conversation where, instead of each person listening to everyone else individually, there’s a running summary of the discussion that gets updated as each person speaks. When a new person contributes, they read from — or update — this summary of prior points, rather than processing every past remark one by one. This running summary plays the role of an internal state that carries information forward. Indeed, mathematically, linear attention can be seen as a form of recurrent neural network: it maintains a hidden state — a matrix that accumulates past key–value information — that gets updated with each new token. This means the model doesn’t need to store all past tokens’ data; it only stores the evolving summary state. The benefit is dramatic: time complexity drops from O(n²) to O(n·d²) in one common setup — linear in sequence length, with d being the state dimension — and memory requirements drop from storing n items to a fixed-size state.
Linear attention’s efficiency comes with trade-offs. By compressing all past information into a fixed-size state, the model inevitably loses some detail. Consequently, early linear attention struggled on tasks requiring precise, content-based reasoning or recall — for example, accurately retrieving a particular fact from far back in a sequence.
One major advance in this evolution is Mamba, a model that achieves linear-time sequence processing without using traditional attention at all. Mamba is built on state-space models — SSMs — a class of models that come from continuous dynamical systems and can be thought of as fancy RNNs capable of handling long-range dependencies. We can extend our earlier analogy: if linear attention was a single notepad summarizing the conversation, Mamba is like a notepad with a smart scribe who actively decides what to write down or erase based on each new statement.
While Mamba outperforms self-attention in language modeling, it still inherently struggles with recall. This limitation is why Self-Attention is hard to abandon entirely. This leads us to the development of hybrid architectures — systems that combine Linear Attention layers with traditional Attention layers, thereby mitigating the disadvantages of both methods.
Before going further, the ways models are usually assessed and benchmarked against one another needs to be explained.
Training and Evaluation Methodology
During the training of a deep learning model, the objective is to reduce a loss function which quantifies prediction inaccuracies.
When assessing different models, their performance is gauged on a validation set — a dataset not used during training. This process yields a validation loss value, where a lower score indicates superior performance.
This metric became the target of a community speedrun called modded-NanoGPT, created by Keller Jordan. The goal: reach a target validation loss on FineWeb — a web dataset — as quickly as possible.
For Dragon’s experiments, 770M-parameter models were trained using the modded-NanoGPT codebase. These models were trained to a specific token count (50B) and use AdamW optimizer, aiming to find the best-performing architecture.
However, validation loss alone doesn’t predict real-world performance, especially in terms of recall — see above — as language modelling involves many tasks, that do not all correlate directly with recall.
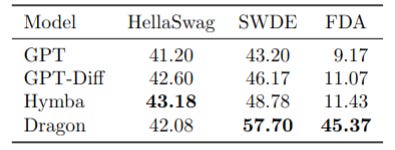
Therefore specific benchmarks were targeted to focus on the recall weakness — see example below. The most prominent ones in the domain are SWDE, FDA, and RULER. Only SWDE (500-token prompts) and FDA (2,000-token prompts) were kept as they proved to be more stable during the evaluation. FDA is more challenging for small models, as it requires retrieving details buried deep in long sequences.
An exemple of SWDE benchmark
Movie name : How to Train Your Dragon: The Hidden World
Director : Dean DeBlois
Set in : The Viking island of Berk and the mythical, hidden dragon realm called the
Hidden World.
Country : United States — DreamWorks Animation production.
Synopsis :Hiccup and Toothless must leave their home and search for the mythical Hidden World to protect the dragons from the villain Grimmel; along the way Toothless meets a Light Fury and Hiccup faces the challenge of letting go.
[...]
Director : {model must answer here}
The benchmark used to evaluate overall language modeling ability was HellaSwag, which tests a model’s capacity to complete a sentence in a coherent and contextually appropriate way.
Once the methodology and benchmarks were set up, the next step was to start building the initial model, starting from the widely used GPT architecture explained above.
Hymba for Efficient Inference
As previously stated, the first big issue of Transformers is their memory issue, this has been studied a lot by the research community. The latest architecture that tried to tackle this issue was presented by NVIDIA and called Hymba.
Hymba is a hybrid architecture that combines in each mixer layer both attention and Mamba — SSM head. It uses only 3 global attention layers, all other attentions can look only at the last 1024 tokens, capping the Self-Attention flops and memory usage. Hence the name Hymba, which is a contraction of Hybrid Mamba.
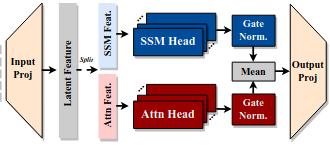
Hymba uses way less memory than alternative Transformers architecture, unlocking very strong inference speed and the ability to share the same hardware for more users, slashing costs.
With longer contexts, the model doesn’t slow down, increasing the performance advantage over other architectures.
When this paper was reproduced, the Mamba component was replaced with Mamba-2 and trained under the same setup as the GPT baseline. The result was both faster inference and better accuracy. Efficiency and performance, usually seen as trade-offs, turned out to reinforce one another.
However, in evaluation of the model pretrained by NVIDIA, very weak recall performance was measured (45.18 for SWDE and 8.6 for FDA).
Let’s dive on what the literature proposes to solve that issue.
Recall Benchmarks and Differential Attention
Inference efficiency is only beneficial if the model can also recall information from its long context. To tackle this issue, the focus was on enhancing the attention mechanism and experimenting with various Self Attention variants to improve recall. Two are worth mentioning — five variants were tested:
Native Sparse Attention by DeepSeek, this variant introduces a mechanism that also reduces the amount of memory that needs to be loaded on the GPU at inference, enabling further efficiency gains. An attempt was made to reproduce the results reported in the paper, but reliable improvements could not be achieved and difficulties were encountered in finding a correct implementation of the paper.
Differential Attention by Microsoft: This can be seen as a noise cancelling headphone, the attention is split in two parts, one that is computing the signal and one the noise, then the noise is subtracted from the signal, effectively increasing the ratio signal/noise which allow the model to find important words in the context more easily.
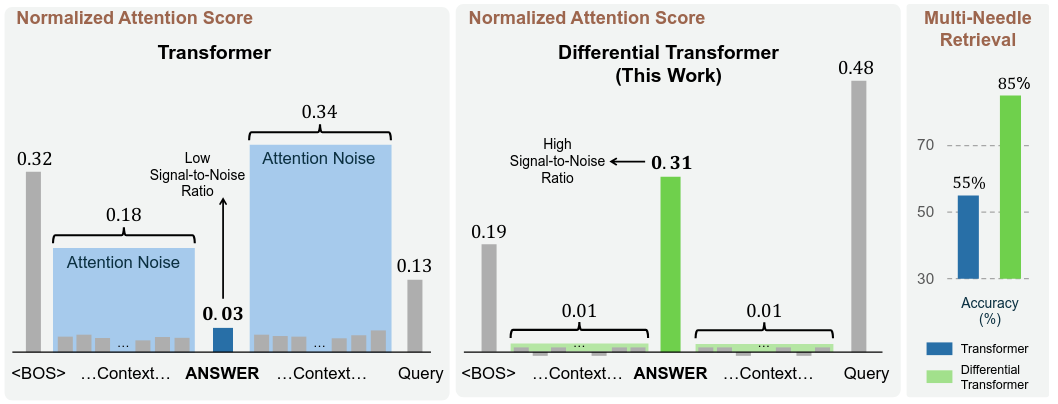
Illustration of the effect of Differential Attention, extracted from the original paper When differential attention was applied on all layers, it produced only marginal improvements, but when differential attention was applied only to global attention, the performance in recall improved dramatically.
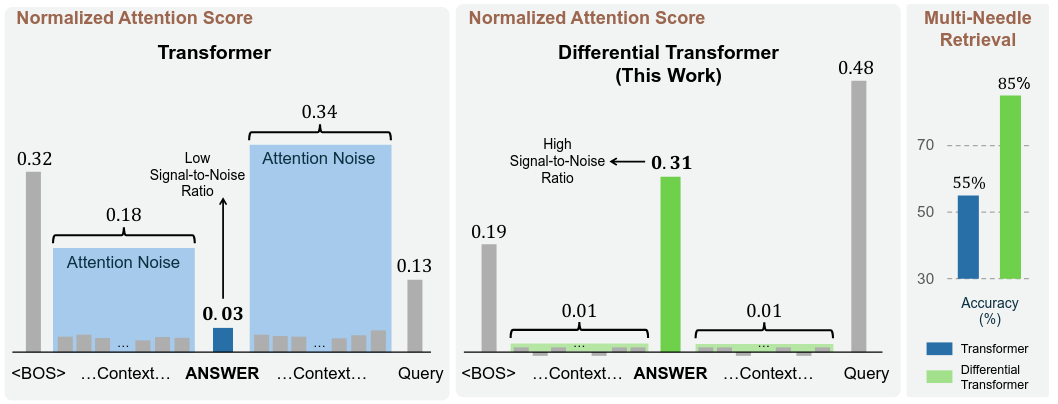
This experiment showed how sensitive recall is to small design adjustments and how published techniques can be adapted to significantly extend long-term memory.
At the question of why it performs so well when applied only on global attention layers, there was no immediate clarity regarding the specific reason, but there are hints that it might help the model to specialize this layers specifically on recall, instead of mixing the role between all layers.
With a trade-off found between computation and recall, the next step was integrating techniques that could improve the global performance of the model.
LayerNorm Scaling: simple but powerful
This paper investigates why most of the performance of the models is concentrated in the first half of the layers, with the second one being almost useless. Their investigation unveils variance instabilities in deep layers of the models, preventing it to train correctly.
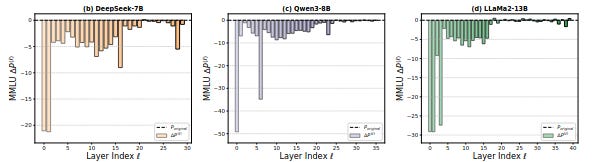
The solution, LayerNorm Scaling, is straightforward: after each pre-normalization, multiply the output by a fixed scalar that depends on the depth of the layer. This stabilizes variance across depth and allows all layers to play their role.
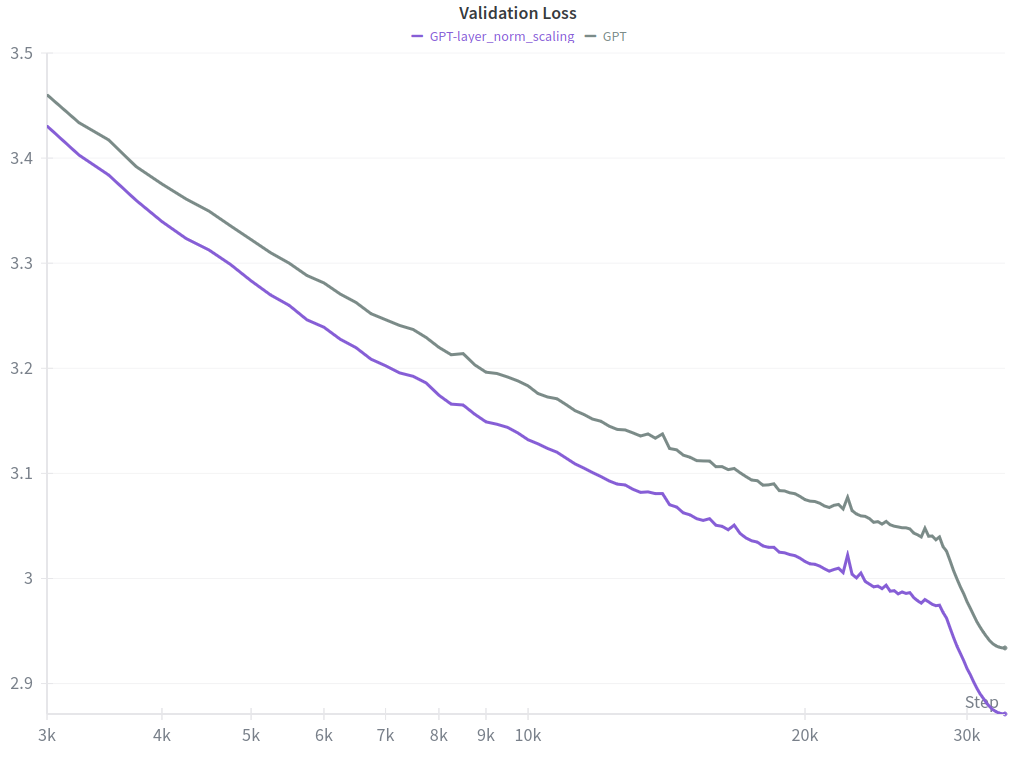
Compared to a the modded-nanoGPT implementation trained with AdamW on 10B tokens, the scaled models not only reached a lower validation loss — which is better — but also improved more steeply over time.
In such conditions, the expectation is that the improvement should grow larger when extending the training to more data.
To wrap this up, a two-line change in the code produced a structural improvement that persisted as models grew.
When building a model, two things matter: the architecture and the training techniques. The latter is the topic of the next section.
Training Techniques
Different training recipes proposed in recent papers were tested. Some worked well; others did not.
Patch-Level Training.
The intuition behind patch-level training is that by grouping tokens into small blocks — say, four at a time — the model processes only a quarter as many positions per forward pass. The representation of each block is then used to predict the next block of tokens. For the same batch size, the compute cost drops by roughly a factor of four, which makes training much more efficient.
In practice, the original paper described two different regimes. In a data-constrained regime (yellow curve below) where the dataset is fixed and compute is the main bottleneck, the recommendation is to spend the first 25% of training steps in patch-level mode. Because these early steps are four times cheaper, the total compute drops to about 80% of the baseline while achieving better performance.
In a data-unconstrained regime (grey curve below) where the priority is to spend the same amount of compute as the baseline, the situation changes. Here, one can afford to use patch-level training for a much larger portion of training (up to 66% of the steps) before switching back to token-level processing. This leads to consuming more data overall, but results in the strongest gains compared to standard training.
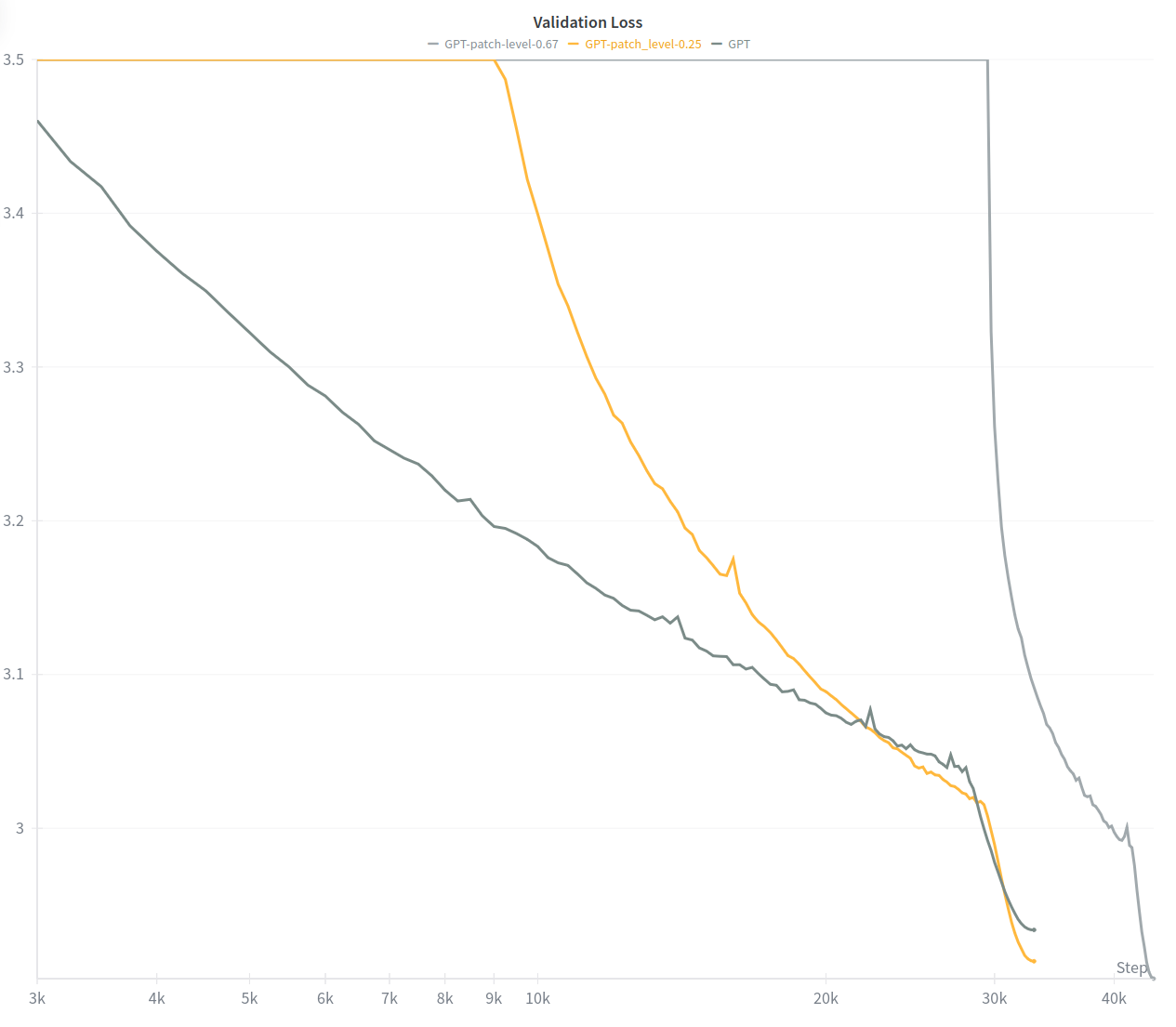
The research team were able to successfully reproduce the gains in plain GPT baselines, but the method consistently failed when applied to hybrid architectures like the model proposed. Further exploration is needed to understand the struggle of Linear Attention variants with this form of training.
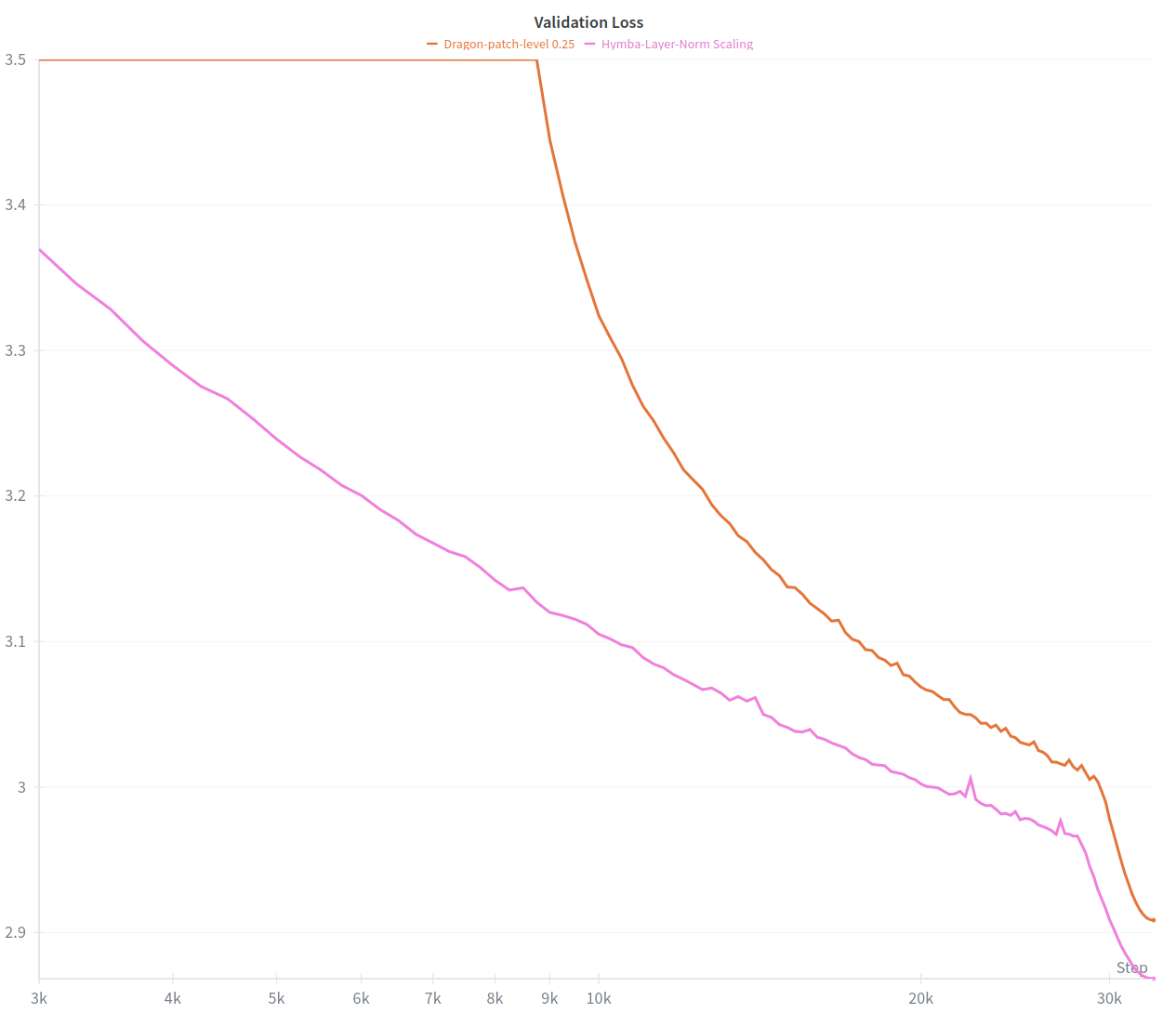
In other words, although this experiment was a dead-end, the intermediate results were promising enough to put it aside, and explore it further later on.
DeepSeek Initialization and SkyLadder Scheduling.
The DeepSeek Intialization consists in replacing PyTorch’s default parameter initialization with the scheme proposed by DeepSeek, consistent improvements were observed at no additional cost. However on short horizon it might degrade performance.
Skyladder Scheduling is a technique to begin training with short attention window and gradually expand it. It acts as a form of curriculum learning and reduces FLOPs by up to 20% in long-context training.
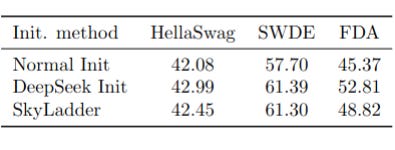
Both these techniques achieved remarkable performance improvement, and generalized well across all our diverse experiment.
Data Efficiency techniques
There was further experimentation with a hybrid of Rho-1 and SoftDedup, two approaches designed to make training more efficient by reweighting tokens. The idea is to use a small model to score each token and adjust its contribution to the loss accordingly, so that more informative tokens influence the gradients more strongly. In principle, this should reduce redundancy in the data and speed up learning. In practice, however, these attempts did not yield improvements. The scoring model used was smaller and trained on fewer tokens than the target models, and this mismatch likely limited its effectiveness.
Neither of these techniques was kept as no promising results were found.
Optimizers
A range of recently proposed optimizers was explored , including Muon — both the standard version and the Moonlight variant with weight decay — SPAM, Stable SPAM, MARS, Ademamix and others. Despite their theoretical advantages, none of them outperformed a carefully tuned AdamW in our experiments at the exception of Ademamix. However training instabilities with the latter were much more difficult to handle, raising concern on its ability to train at larger scale. Therefore it was not kept.
For this hybrid architecture, the previously established baseline remained the most reliable choice.
More technical Architectural Refinements
For completeness, other technical changes were applied inside the architecture. They will be not detailed in this article.
Gated Delta Net — GDN: replacing Mamba-2 with a smarter internal-state management, better performance once training exceeded ~30B tokens.
Repositioned global layers: placing them at thirds of the network, following Hymba-1.5’s recipe, improved both loss and recall.
Norm per head — Headwise Norm: normalizing attention heads individually improved signal integrity and non-linearity, a design later confirmed by Qwen’s Gated Attention.
NoPE for global heads: improved results on RULER when combined with small-base RoPE for local heads.
QK Norm with Scalable Softmax: mitigated “attention fading” by keeping probability distributions sharp as context length grows.
Together, these refinements consistently lowered validation loss compared to GPT baselines.
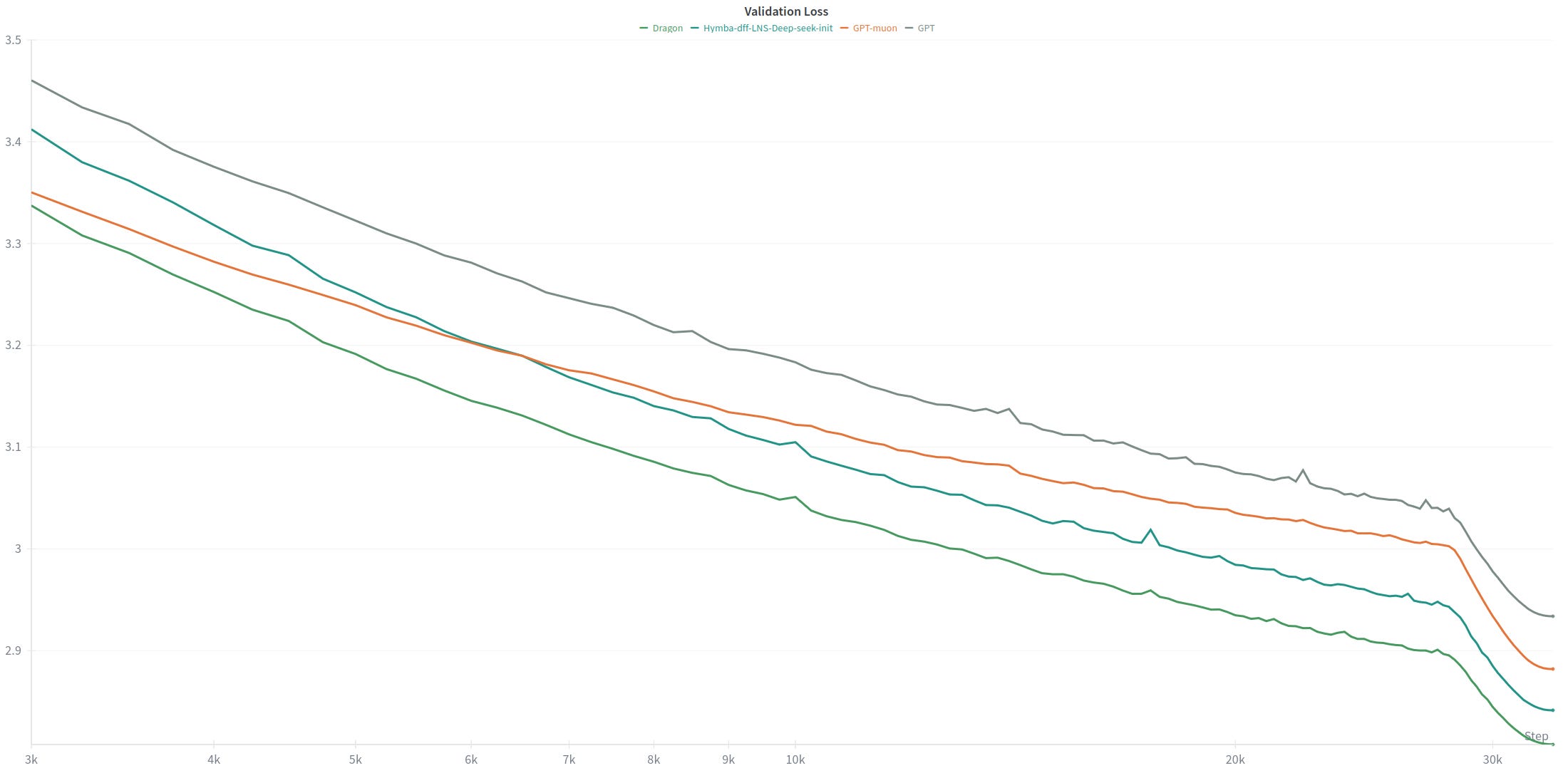
The grey curve represents the standard GPT architecture.
The orange curve shows the best-performing model from the modded NanoGPT speedrun — the base GPT architecture trained with the Muon optimizer.
The blue curve corresponds to the Dragon architecture, incorporating the improvements described in this article.
The green curve represents the final version of Dragon, including the additional optimizations mentioned above.
In other words, the improvement from GPT to Dragon is dramatic. Now the big question is : will it perform as well at scale ?
Scaling to Billions of Parameters
Most experiments were run at 120M–770M scale on up to 50B tokens. To test whether these improvements held at real-life scales, the architecture was implemented inside Megatron-LM. Megatron-LM is a training framework written by NVIDIA. It is extremely efficient in breaking down the work of training the model on hundreds of computers. In comparison, modded-NanoGPT could only perform on 10s of GPUs.
A 3.6B parameter Dragon model was trained on 3.7T open-source tokens and compared to Qwen3-4B and SmolLM-3, two state-of-the-art models at that scale
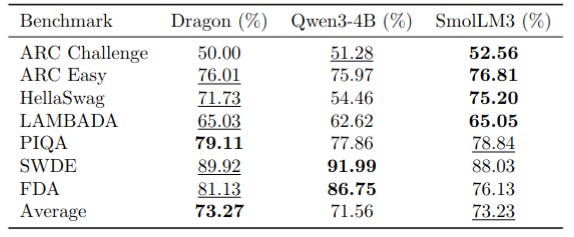
Overall, Dragon performs on par with Qwen3 and SmolLM3 while being trained on 3 times less data compared to SmolLM3 and 10 times less compared to Qwen.
Nevertheless, two shortcomings in the model were identified : mathematics and code. These issues were linked to an error in the tokenizers, that will be fixed in the next models, and it is anticipated that the performance gap in those two category will close.
What Comes Next
The next step is to scale further both in parameters and training horizons — more tokens. Competing models are trained on 10T+ tokens, and post-training is required to transform a pretrained model into a useful assistant. The strategy is to:
Train Dragon on trillions more tokens,
Post-train for instruction following and practical use cases,
Explore larger parameter counts to verify scaling behavior.
Literature review of Architectures
During the training of the Dragon model, other interesting architectures were released:
Falcon-H1: A family of models that is very close to Hymba with global attention at each layer, showing very strong performance.
Deepseek v3.2: Comes with an attention that reduces the KV cache and with a selection mechanism to reduce the number of tokens to load, this is clearly a path which will be explored for further Dragon models.
Qwen3-next: Also very efficient, reusing some of the work presented here, GDN, Gated Attention, etc.
Phi4-mini-flash: Implements differential attention in a hybrid architecture.
Conclusion
Most research in deep learning never makes it into production models — not because it lacks merit, but because integration is complex. Dragon shows what happens when this gap is bridged: by merging key innovations from recent literature — hybrid attention, differential mechanisms, normalization scaling, and efficient training recipes — Dragon LLM builds a model that’s both faster and smarter.
The result is not just an academic experiment but a production-ready architecture proving that the frontier of LLM design still moves forward. The next challenge is to scale Dragon further, turning this research-driven foundation into the next generation of efficient, high-performing large language models.
If you’ve read this far, you may want to subscribe to stay informed about our upcoming releases and research findings.
About us
Founded in 2011 under the name Lingua Custodia to target the financial industry, Dragon LLM is a French company specialized in frugal and sovereign AI models & architectures.
Winner of the Large AI Grand Challenge organised by the European Commission, Dragon LLM designs efficient and economical AI models, adapted to business practises and deployed on local infrastructures. Based in Paris, the company aims to build a useful, responsible and efficient European AI, at the service of companies while promoting the technological sovereignty of the continent.
Dragon LLM offers specialized and sovereign models for direct usage by the technical teams of its customers and a SaaS platform allowing business users to directly use its generative AI technologies to analyse unstructured financial information, translate, classify, summarise or compare technical documents securely.
If you want to access our secure and sovereign technology, or adapt a model to a specific domain or tasks get in touch : contact@dragonllm.ai